PS4: Recommender Systems
This problem set is an opportunity to build a recommender system from Yelp restaurant review data. As in all problem sets, you may work in pairs, but if you have worked with the same partner 3 times so far, you must find someone new. Use the search for teammates post on Piazza to find partners.
Our data comes from this year's Yelp Dataset Challenge, an annual contest for students to draw creative insights about Yelp reviews and restaurants by applying machine learning and data analysis. I encourage you to consider working on this data for your final project, and submitting it to the contest (due, conveniently, in June) -- cash prizes and fame await!
The training data includes ratings on or before September 2016, while the test data are ratings on October, November and December 2016.
Objective
Understand and implement different algorithms for recommender systems.Setup
Click the repository link at the top of the page while logged on to GitHub. This should create a new private repository for you with the skeleton code.
If you are working in a pair, go the Settings > Collaborators and Teams in your repository and add your partner as a collaborator. You will work on and submit the code in this repository together. Each pair should only have one repository for this problem set; delete any others lying around.
Clone this repository to your computer to start working. Commit your changes early and often! There's no separate submission step: just fill out honorcode.py and README.md, and commit. The last commit before the deadline will be graded, unless you increment the LateDays variable in honorcode.py.
See the workflow and commands for managing your Git repository and making submissions.
Download data.zip from this location, unzip it (creating a folder named data), and place it in the directory where you cloned your repository. Do not commit this folder. It contains the files train.csv and test.csv with three columns each: user ID, business ID, and ground truth rating. The files user_reviews.json and item_reviews.json contain the review text by each user and for each business, which you'll use for content-based recommendations.
Part A: Collaborative Filtering [25 pts]
This section builds models to predict the rating that a user will give to a business.
Implement the baseline, user-based, and item-based collaborative filtering
functions in collabfilter.py to predict ratings on the test data,
write a CSV output file with the predicted ratings, and return the mean squared errors.
(Some docstrings may say "mean squared accuracy" -- this is a typo, and you must actually return the error instead.)
Possible metrics for the collaborative filtering functions are "jaccard" and "cosine" (you need not implement the Pearson correlation coefficient).
Keep in mind that both the similarity metrics should ignore non-rated user-item pairs.
Part B: Content-Based Recommendation [25 pts]
This section builds a content-based model from review text to predict whether a user will visit a business. We define a visit as a user leaving a review for that business.
All code is to be written in wordusage.py.
Unlike previous problem sets, exact function contracts aren't
provided, so you're free to structure your program however you wish.
The only specified function is rec_pr_curve.
user_reviews.json maps each user to the text (as a list of words) of all their reviews from the training data, and item_reviews.json maps each business to the text of all its reviews. Implement a function to featurize this data as bag-of-words with TF-IDF weighting as described in class, lowercasing all the words, and ignoring words that occur in fewer than 50 users or items in total.
You may use sklearn's featurizer, or other ready-made functions to help with this featurization. If you do use sklearn, the TF-IDF vectorizer will return a sparse array. To convert it to a normal, "dense" respresentation, invoke the toarray() method.
Next, write a function that takes a similarity threshold as a parameter (in addition to any other arguments you wish to supply), and for every user in the test.csv, computes the subset of businesses, of the businesses present in test.csv, whose cosine similarity with the user according to the text features is above the threshold. These are the business that will be suggested to the user.
Finally, define the function rec_pr_curve
that compares the recommended businesses for each user
with the actual businesses that they visited (i.e., rated)
in test.csv,
and computes precision and recall (averaged across all users).
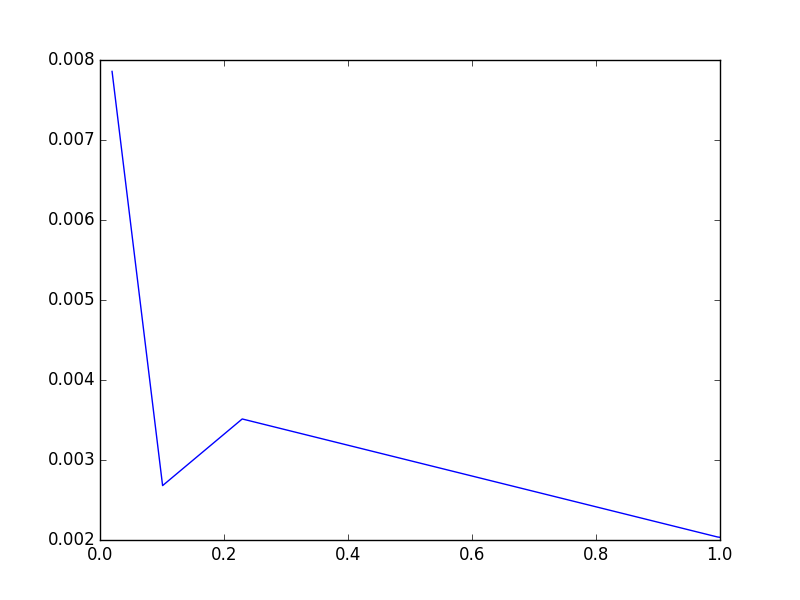
This function should plot the precision on the y-axis and the recall on the x-axis
for values [0.3, 0.6, 0.9, 0.92, 0.95] of the similarity threshold, and
save it as filename.
Here's the expected plot:
No analysis this week! Complete honorcode.py and README.md and push your code by Fri, Mar 10th at 11:00 pm EST